
Imagine the following situation: a third party service is generating some files for your application and notifies you that the file is now ready to download via web hook. This service has no idea of you business logic and doesn’t really care either. So all you get from the web hook’s request is the filename. But somehow, you need to be able to identify the related entity in your application’s database again and set additional parameters on entity side. How would you accomplish this?
I will present three different ways to you how to extract data from a filename (or string). So let’s grab a coffee and talk about: data extraction.
Prerequisites
All three methods will only work if you have expectations about how the filename might look like. If you expect something like 12345-filename.jpg and you get filename_0a673b0c-8445-4f66-a9a9-c5000d93c965.jpg instead, you won’t have any chance to automatically extract the right information. So let’s assume that there are certain rules of how the files are named that are notified to your web hook.
Define separation markers
If you have any possibility to influence the naming of the files, you might want to define a character which must not be part of any data field in the file name. For example, you could set a rule that the _ underscore symbol shall be used to separate all data parts of the filename:
12345_v2_filename-with-a-human-readable-description_Q8C.mp4 12345_audio_filename_highQuality.mp3 12345_video_filename_lowQuality.ogg file_12345.gif
Then we could split the string on the _ character and receive all parts of the filename after we removed the last four characters (i.e., the file ending) of the string.
$input = '12345_v2_filename-with-a-human-readable-description_Q8C.mp4';
$fileWithoutFileEnding = substr($input, 0, -4);
list($id, $version, $filename, $quality) = explode('_', $fileWithoutFileEnding);Issue 1: What if the file ending is of variable length?
We might have files with different file extensions. For example subtitle formats (vtt, srt, ttml) or image formats (svg, gif, jpeg). The easiest should would be to agree on a second rule that the filename must not contain any . characters. Then you can split on the dot symbol and extract the file extension with ease:
$input = '12345_v2_filename-with-a-human-readable-description_Q8C.mp4';
list($fileWithoutFileEnding, $extension) = explode('.', $input);
list($id, $version, $filename, $quality) = explode('_', $fileWithoutFileEnding);If this is not possible, you could at least look for the last . in the input filename which does or does not work depending on your situation (e.g., .tar.gz).
Issue 2: What if some parts are null or optional?
When optional fields are still recognizable, that means, when optional fields are included as an empty string in the filename you should be fine.
// $version = 'v2' "12345_v2_filename-with-a-human-readable-description_Q8C.mp4" // $version = '' "12345__filename-with-a-human-readable-description_Q8C.mp4"
Substring parts?
But when this is not the case or the order is not always the same, the best bet is to prefix certain fields or extract data by certain characteristics that you know (e.g., the id is the only field only consisting of numbers, or, the quality always starts with a capital “Q”).
$input = '12345__filename-with-a-human-readable-description_Q8C.mp4'; $id = substr($input, 0, 5); // "12345" $qualityStart = strpos($input, "_Q") + 1; // find position of Q $qualityEnd = strpos($input, '.', $qualityStart); // find "." behind "Q" $quality = substr($input, $qualityStart, $qualityEnd - $qualityStart); // "Q8C"
As you can see, this is doable but gets messy almost instantly and barely readable. This is why I wouldn’t recommend this solution to anyone!
Regex to the rescue!
Regular expressions have a reputation of being immensely complicated and a lot of developers try to avoid them at every cost. It make take you a while to read them or get some of edge cases right but it is absolutely worth it investing a little time to learn regular expressions! They can save you a lot of time when manually transformation big text files (e.g., log files, JSON or CSV data). Furthermore, they can be very useful for our use case here! You get two benefits from using regex:
- Validation of the filename schema If the filename does not have the right schema to be parsed with your regular expression, you can add error handling for this scenario and don’t need to try to parse erroneous content. On top of that, if you think back to the strategy pattern we used in the Refactoring challenge, you could even use the validation to decide which kind of handler/strategy needs to be used for a certain filename (and otherwise abort).
- Extraction of all named sub-patterns That’s right! You’re not only getting all the pattern matches for a single line of
preg_match_all, you can also name the pattern and address them like an associative array!
In order to define the regex, we need to have a look at all partitions of our input string and see which rules apply to each part:
Video:
{id}_{version}_{description}_{quality}.{fileExtension}
id: series of integers
version: starts with the character "v" continued by integers
description: a longer string with alphanumeric characters and dashes
quality: always starts if a capital Q. In our case we only have 4 possible inputs: Q4A, Q6A, Q8C, QXB
extension: mp4 or webm
Now, we can work on our regex. I recommend you to use a regex-tester like https://regexr.com/ or https://regex101.com/. Both are great choices to directly test your regex against several test strings and you even have a cheat sheet and explanation module for your regex! Additionally, you can even share your regular expressions and discuss with colleagues if the regex is suitable or if you missed any edge cases. Regex101 even has a “Code Generator” for several programming languages to directly use them in your code.
From the rules we defined above, I was able to create the following regular expression:
(?P<id>\\d+)_(?<version>v\\d+)_(?P<description>\\S+)_(?P<quality>(?i)Q4A|Q6A|Q8C|QXB).(?<extension>(?i)mp4|webm)
And with Regex101, I could already test if it’s working as expected: https://regex101.com/r/3BJwyj/1/
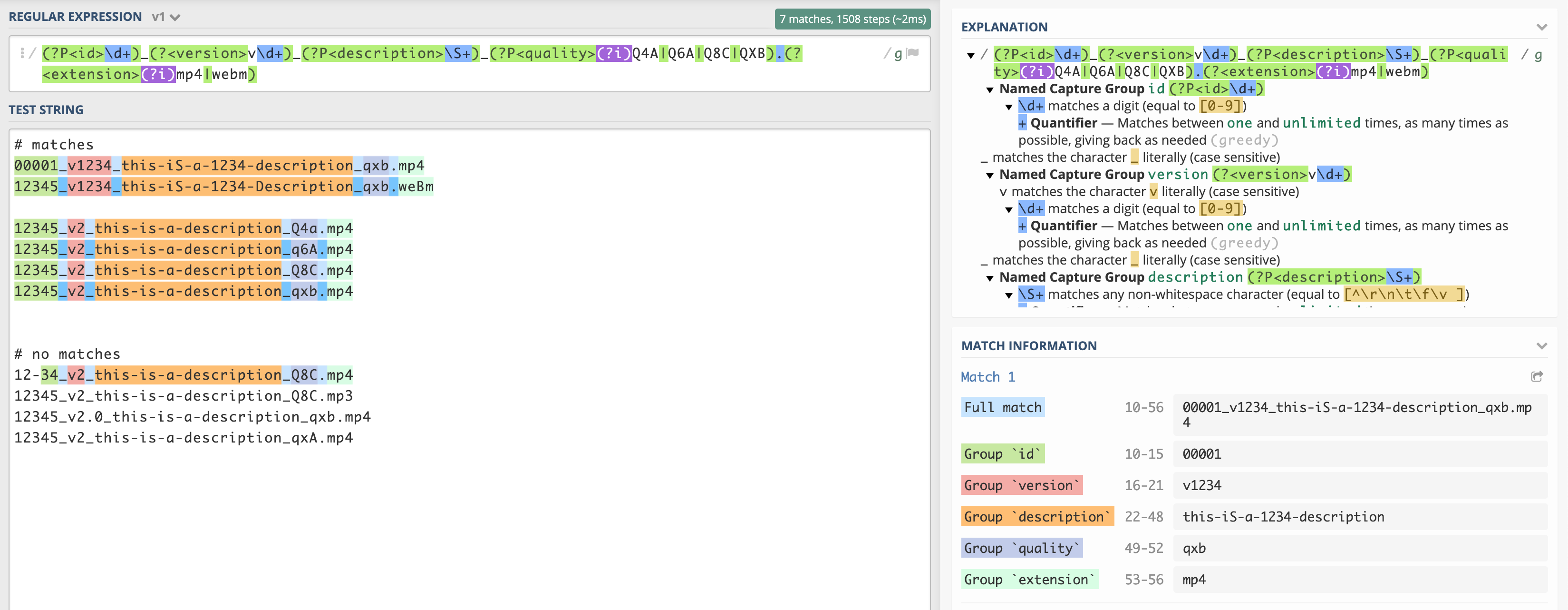
The same approach can now be used for the image type or the audio type that were mentioned above in this article. I would recommend you to store your regular expressions in constants inside a suitable class, so you can reuse them easily throughout your project. I promise you, it will be far easier to identify which regular expression you are using when reading the constant’s name instead of trying to decipher the regex!
Practise
With the conclusion from above, I want to revisit the Refactoring Challenge 1. There are two occurrences where I needed to extract parameters from the filename. Let’s put our knowledge from above to good use and refactor these:
// e.g. "image_12345.png" $filename = $distributionDTO->getFilename(); $firstUnderscore = strpos($filename, '_'); $sU = strpos($filename, '.', $firstUnderscore + 1); $id = (int)substr($filename, $firstUnderscore + 1, $sU - $firstUnderscore - 1); $image = $this->repository->getImageById($id);
// .e.g. "video_12345_q8c.mp4" $filename = $distributionDTO->getFilename(); $firstUnderscore = strpos($filename, '_'); $secondUnderscore = strpos($filename, '_', $firstUnderscore + 1); $id = (int)substr($filename, $firstUnderscore + 1, $secondUnderscore - $firstUnderscore - 1); $video = $this->repository->getVideoById($id);
The filenames mentioned in the [README.md](<http://readme.md>) are very simple! The regular expressions shouldn’t be too complicated…
With this regular expression, I decided to add a new class FilenameDataExtractor which sole purpose is to extract parameters from a string by applying a given regular expression:
<?php
namespace App\\Distribution;
use App\\Exception\\FilenameParseException;
class FilenameDataExtractor
{
public static function getIdFromFilename(string $filename, string $regex): int
{
$matches = [];
preg_match($regex, $filename, $matches);
if (!isset($matches['id'])) {
throw new FilenameParseException("Could not extract id from {$filename} with {$regex}");
}
return (int)$matches['id'];
}
public static function getParametersFromRegex(array $parameters, string $filename, string $regex): array
{
$matches = [];
preg_match($regex, $filename, $matches);
$result = [];
foreach ($parameters as $parameter) {
if (!isset($matches[$parameter])) {
throw new \\InvalidArgumentException("Unable to extract {$parameter} from filename: {$filename}");
}
$result[] = $matches[$parameter];
}
return $result;
}
}
I’ve added two methods. One for only getting the id, one for getting a set of parameters as an array. With these methods, the code from above can be simplified to this:
const REGEX_VIDEO_FILENAME = '/video_(?P<id>\\d+)_(?P<quality>(?i)q4a|q6a|q8c|qxa|qxb).(?P<extension>(?i)mp4|webm)/'; const REGEX_IMAGE_FILENAME = '/image_(?P<id>\\d+)\\.(?P<extension>(?i)gif|png|jpg|jpeg)/';
$id = FilenameDataExtractor::getIdFromFilename(
$distributionDTO->getFilename(),
DistributionDTO::REGEX_VIDEO_FILENAME
);
$video = $this->repository->getVideoById($id);
$id = FilenameDataExtractor::getIdFromFilename(
$distributionDTO->getFilename(),
DistributionDTO::REGEX_IMAGE_FILENAME
);
$image = $this->repository->getImageById($id);
Summary
That looks a lot more readable now, doesn’t it? Additionally, you can add unit tests solely for testing if the parameters are parsed properly from your regex. By doing this, we were able to move the extraction-logic out of the distribution strategies and even made the code more reusable!
Regular expressions are a great tool and if you don’t have a lot of experience with it yet or tried to avoid it in the past, I hope this post gave you one more reason to have another look into the topic. I can promise you, it will help you a lot!
Happy regex-ing everyone! 🙂


